これはなに
- JanusGraphとはオープンソースのGraphDBです
- 今回はGraphOfTheGods(神々のグラフ)を使って、GraphDBをローカルで試す方法を紹介します
- この内容は主に https://docs.janusgraph.org/ の公式情報を日本語で簡略化したものです
- GraphDBに興味のある方は絶賛採用中なので、こちらのブログも参照してください!
🤝 恋愛を「友だちの繋がり」で技術的に支援するサービスのバックエンド開発に力を貸してください! - Diverse developer blog
GraphOfTheGodsとは
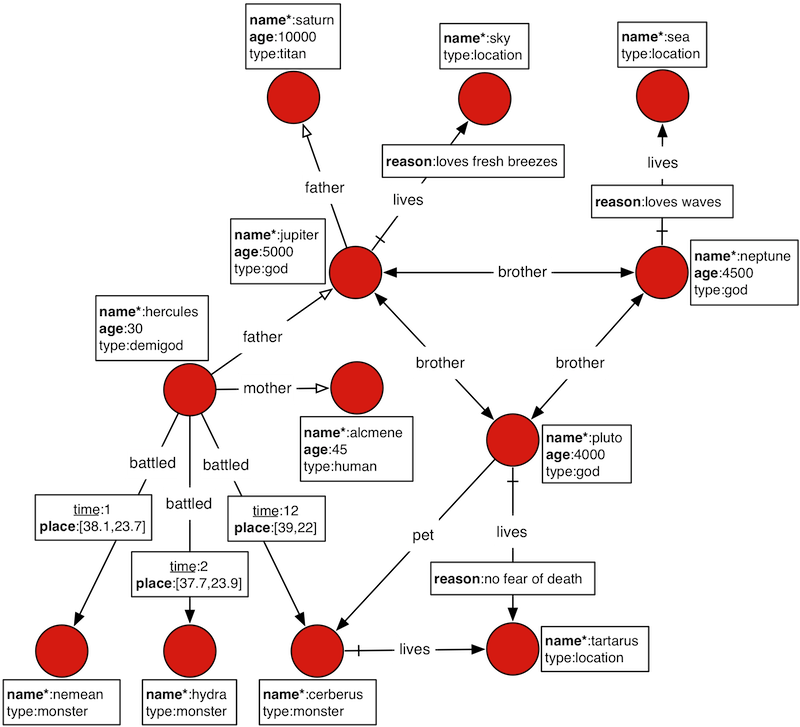
GraphOfTheGods(神々のグラフ)はJanusGraphが公式で紹介している代表的なチュートリアルです。文章で説明するより、公式サイトの図を見る方が理解しやすいので、下記にその図を引用します。
図によれば、hercules(ヘラクレス)の父はjupiter(ゼウス)で母はalcmene(アルクメーネー)です。そして、herculesはhydra(ヒドラ)とギリシャのサロニコス湾付近(北緯37.7 東経23.9)で戦っています。人間関係だけでなく、出来事までデータが関連しています。GraphDBの特徴を理解できる素晴らしいチュートリアルです。
セットアップ
1. Docker
まずはDocker Desktopをローカルにインストールします。https://docs.docker.com/get-docker/ から対応するプラットフォームを選んでインストールしてください。以後、ここからはMacで説明を進めます。
Docker Desktopをインストールできたら、Docker DesktopからDockerを起動してください。
2. janusgraph-docker
docker専用のJanusGraphのリポジトリをローカルにクローンします。
$ git clone git@github.com:JanusGraph/janusgraph-docker.git
3. コンテナを起動
janusgraph-dockerのmasterブランチで下記のコマンドを実行します。
$ docker run --name janusgraph-default -p 8182:8182 janusgraph/janusgraph:latest
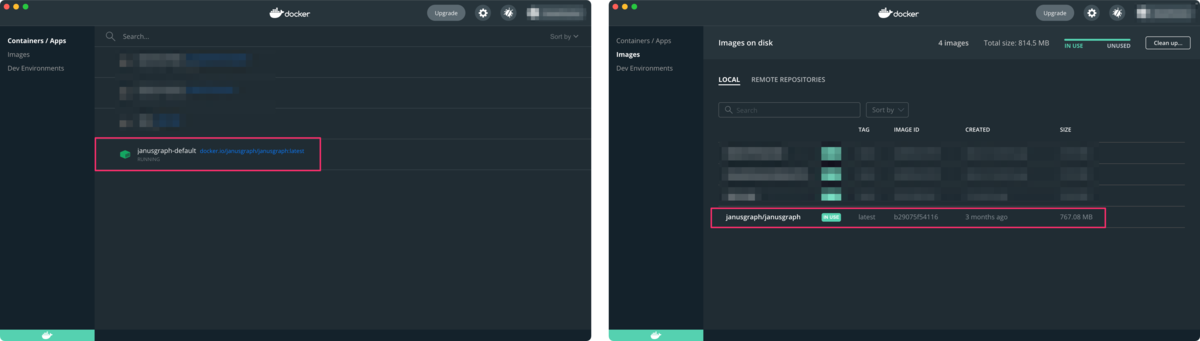
しばらくすると、下記のコンテナとイメージが作成されます。
| Docker Desktopで見えるコンテナとイメージ |
 |
4. Gremlin Consoleに接続
ターミナルで操作している場合、もう一つ別のタブを開いてjanusgraph-dockerのmasterブランチで下記のコマンドを実行します。
$ docker run --rm --link janusgraph-default:janusgraph -e GREMLIN_REMOTE_HOSTS=janusgraph --name gremlin-console -it janusgraph/janusgraph:latest ./bin/gremlin.sh
実行すると、Gremlin Consoleが起動するので、ターミナルからGraphDBにクエリを実行することが可能になります。
$ docker run --rm --link janusgraph-default:janusgraph -e GREMLIN_REMOTE_HOSTS=janusgraph -it janusgraph/janusgraph:latest ./bin/gremlin.sh
Jun 22, 2021 3:42:27 AM java.util.prefs.FileSystemPreferences$1 run
INFO: Created user preferences directory.
\,,,/
(o o)
-----oOOo-(3)-oOOo-----
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/janusgraph/lib/slf4j-log4j12-1.7.12.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/janusgraph/lib/logback-classic-1.1.3.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
plugin activated: tinkerpop.server
plugin activated: tinkerpop.tinkergraph
03:42:32 WARN org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
plugin activated: tinkerpop.hadoop
plugin activated: tinkerpop.spark
plugin activated: tinkerpop.utilities
plugin activated: janusgraph.imports
gremlin>
ここでGremlinという聞き慣れない名前が出ました。Gremlinとはグラフデータベース操作言語です。RMDBのSQLと似たようなものです。詳細な説明はこちらのサイトを参照してください。
5. GraphOfTheGodsをロードする
起動したGremlin Consoleに下記のコマンドを実行して、GraphOfTheGodsのデータをロードします。今回はGremlinをすぐに実行してデータ構造を理解するために、インデックス無しでデータをロードします。
gremlin> graph = JanusGraphFactory.open('conf/janusgraph-inmemory.properties')
==>standardjanusgraph[inmemory:[127.0.0.1]]
gremlin> GraphOfTheGodsFactory.loadWithoutMixedIndex(graph, true)
==>null
gremlin> g = graph.traversal()
==>graphtraversalsource[standardjanusgraph[inmemory:[127.0.0.1]], standard]
gremlin>
これでGraphOfTheGodsのデータがローカルで確認できるようになりました。
クエリを実行してみる
1. 簡単なクエリ
まずはGraphOfTheGodsのデータが正しくロードされたのか確認します。
gremlin> g.V().count()
04:19:21 WARN org.janusgraph.graphdb.transaction.StandardJanusGraphTx - Query requires iterating over all vertices [()]. For better performance, use indexes
==>12
gremlin>
g.V().count() とは、頂点(vertex)の数です。最初の図で言うと、赤丸の数と同じです。RMDBだと行みたいなものです。さらにデータを見てみましょう。
gremlin> g.V().values('name')
04:26:52 WARN org.janusgraph.graphdb.transaction.StandardJanusGraphTx - Query requires iterating over all vertices [()]. For better performance, use indexes
==>sky
==>hydra
==>cerberus
==>neptune
==>alcmene
==>jupiter
==>pluto
==>sea
==>saturn
==>hercules
==>nemean
==>tartarus
gremlin>
それぞれの頂点から name プロパティを取得しました。神やモンスターや場所の名前が一覧で出てきましたね。
より詳細に確認するならスキーマを見ると良いでしょう。
gremlin> mgmt = graph.openManagement()
==>org.janusgraph.graphdb.database.management.ManagementSystem@62b09715
gremlin> mgmt.printSchema()
==>------------------------------------------------------------------------------------------------
Vertex Label Name | Partitioned | Static |
---------------------------------------------------------------------------------------------------
titan | false | false |
location | false | false |
god | false | false |
demigod | false | false |
human | false | false |
monster | false | false |
---------------------------------------------------------------------------------------------------
Edge Label Name | Directed | Unidirected | Multiplicity |
---------------------------------------------------------------------------------------------------
father | true | false | MANY2ONE |
mother | true | false | MANY2ONE |
battled | true | false | MULTI |
lives | true | false | MULTI |
pet | true | false | MULTI |
brother | true | false | MULTI |
---------------------------------------------------------------------------------------------------
Property Key Name | Cardinality | Data Type |
---------------------------------------------------------------------------------------------------
name | SINGLE | class java.lang.String |
age | SINGLE | class java.lang.Integer |
time | SINGLE | class java.lang.Integer |
reason | SINGLE | class java.lang.String |
place | SINGLE | class org.janusgraph.core.attribute.Geoshape |
---------------------------------------------------------------------------------------------------
Vertex Index Name | Type | Unique | Backing | Key: Status |
---------------------------------------------------------------------------------------------------
name | Composite | true | internalindex | name: ENABLED |
---------------------------------------------------------------------------------------------------
Edge Index (VCI) Name | Type | Unique | Backing | Key: Status |
---------------------------------------------------------------------------------------------------
---------------------------------------------------------------------------------------------------
Relation Index | Type | Direction | Sort Key | Order | Status |
---------------------------------------------------------------------------------------------------
battlesByTime | battled | BOTH | time | desc | ENABLED |
---------------------------------------------------------------------------------------------------
gremlin>
なんとなくデータの構造が見えてきますね。
いくつかの簡単なクエリで、データがロードされてることが確認できました。
2. 任意のデータ(vertex)だけ取り出す
もう少しクエリを実行してみます。
gremlin> g.V().has('name', 'jupiter').values('age')
==>5000
gremlin>
jupiter(ゼウス)の年齢を取得しました。5000歳です。今度はjupiterの頂点(vertex)そのものを取得してみます。
gremlin> jupiterV = g.V().has('name', 'jupiter').next()
==>v[4208]
gremlin> g.V(jupiterV).valueMap()
==>[name:[jupiter],age:[5000]]
gremlin>
少し複雑になってきました。 g.V().has('name', 'jupiter') はjupiterを指定して .next() で jupiterV に入れました。このように変数へ代入するような書き方が、グラフDBでは一般的な書き方のようです。公式では、これを「エントリーポイントを指定する」と表現しています。
The typical pattern for accessing data in a graph database is to first locate the entry point into the graph using a graph index. That entry point is an element (or set of elements) — i.e. a vertex or edge. https://docs.janusgraph.org/getting-started/basic-usage/#global-graph-indices
3. 関係(edge)をたどる
グラフDBの強みであるデータ同士の関係をたどってみます。
gremlin> g.V(jupiterV).out('father').values('name')
==>saturn
gremlin> g.V(jupiterV).in('father').values('name')
==>hercules
gremlin>
jupiter(ゼウス)を起点に考えます。jupiterの父はsaturn(サートゥルヌス)です。さらに、hercules(ヘラクレス)の父はjupiterです。上記の図で言うと、out と in がjupiterに関係する矢印の向き(関係= edge)と対応しています。そして、saturnはherculesの祖父であり、herculesはsaturnの孫とも言えます。この関係をクエリで書くと以下のようになります。
gremlin> saturn = g.V().has('name', 'saturn').next()
==>v[4336]
gremlin> hercules = g.V(saturn).repeat(__.in('father')).times(2).next()
==>v[8432]
gremlin> g.V(hercules).valueMap()
==>[name:[hercules],age:[30]]
gremlin>
saturnを起点にして、孫のherculesのプロパティを取得して表示しました。
終わりに
チュートリアルをなぞっただけですが、これで自分のPCにGraphDBのデータベースを構築できました。興味のある方はローマ神話とGraphDBを学べるお得なチュートリアルなので是非トライしてみてください。最後に、Gremlin Consoleを閉じておきましょう。
gremlin> :exit
しかし、実際にサービスで利用するには、チュートリアルだけでは終われません。任意の初期データの投入や、各種クラウドサービスとの連携などが必要です。
次回はGraphOfTheGodsではなく、任意の初期データの投入してGremlin Consoleを起動して接続する方法を紹介します。
もし、このようなGraphDBに興味のある方は絶賛採用中なので、下記のブログも合わせて読んで応募してください!
developer.diverse-inc.com