こんにちは!Diverse広報担当です!
先日、Diverse Meetup #3となる『Lookerを使ったデータドリブンなアプローチ』を開催しました!

DiverseのiOSエンジニアであり、最新アプリHOPにも関わる熊埜御堂 将隆さんがご登壇!
BIツール「Looker」についての基本、Diverseで展開しているマッチングサービスでの活用法、さらにデータドリブンを実現するためのコツをお話いただきました。
今回は、当イベントの様子を前編・後編に分けてお伝えします。
まずは前編、「Lookerの基本とデータ活用」からどうぞ!
▼目次
当日の資料と動画を公開中!
残念ながら当日参加していただけなかった方のために、資料と動画を公開させていただきます!
- 資料はこちら
- Diverse Meetup #3 前編の動画はこちら www.youtube.com
イベントルポを大公開します
ここからは、当日のイベント(前編)のエッセンスを文字にまとめています。
「動画を見ている時間がない!」「要点だけサラッと理解したい!」という方はこちらをご覧ください!
▼Lookerって何?(00:11)
熊埜御堂 将隆(以下、熊埜御堂):まず「Lookerって何?」というところから説明します。
Looker のサイトを見ると色々書いてありますが、結局できることはBIツールとしての使い方です。
SQL を実行して、特定のデータベースからデータを取ってきたものを表示するという使い方がメインになります。

Lookerには、以下の4つのメリットがあります。
複雑なクエリを人力で書かなくていい(一番大きなメリット!)
定義を意味するLookMLをGit で管理していくためバージョン管理が可能
外部への通知や共有が簡単です(slack に通知やメール配信)
特定のユーザーであればアクセスできる等、テーブルなどにも制御が可能

▼LookMLについて(02:15)
熊埜御堂:LookMLとは、SQLデータベース内のディメンジョン、集計、計算、およびデータ関係を記述するための言語です。

以下ざっくりと説明します。
ディメンジョン:where句で絞り込むためのカラムのようなもの
集計や計算:SQLで言う count~~というもの
データ関係:テーブルとテーブルの関係性のところ、つまりSQL のjoin、left join、inner join にあたります。
ディメンジョン の定義について、参考例をご紹介します。

「gender_code」という性別を表すものについて。
gender_code が1だった場合は男性、2だったら女性と表記するということが、上記の図のように定義できます。
ケース文は自分で書く必要がありますが、一度定義してしまえばずっと使えるので楽ですよ。
続いて、外部通知についてです。
特定の時間を通知する、GoogleのスプレッドシートやGoogleドライブ内にcsvとして書き出すことができます。

Diverseでは、マッチングアプリを扱っているので、異常な回数のアクションをする人や不正なことをする人などを見つけるために使うことが多いです。
▼Diverseの環境について(04:15)
熊埜御堂:Diverseでは、アプリから得られる主なデータを AWS 内にあるMySQL サーバーに貯めています。
それと同時に、 BigQuery や Treasure Data にもデータを飛ばしています。

マッチングアプリでやり取りされる個別のメッセージについては、Treasure Data やBigQuery には送らないようにしています。
個人のプライバシーを含むデータは、AWS だけに置くというルールです。
個人情報をどうしても確認したい場合は redash を使っています。
どうしてもユーザー情報を何かに紐付けたいというケースも出てきます。
その場合に備えて、「AWS からバルクインポート→Treasure Data の方に1つ中間テーブルを作成→ Looker で数字を出せる」という仕組みを作っています。
▼データドリブンなアプローチについて(05:35)
熊埜御堂:「データドリブン」を目指すには、データを触る人がたくさん増えた方がいいと考えています。
ただし「いきなり Looker 触ってください」と言っても、多分使ってもらえないことが多いですよね。
そこで、Diverseではレクチャー用のテーブルを作っています。
最初にお見せするのがこちらのスプレッドシート。ポケモンの初代と最新の情報が混ざっているデータです。
データを触る人は、必ずしもエンジニアではないので、馴染みのあるスプレッドシートにしました。
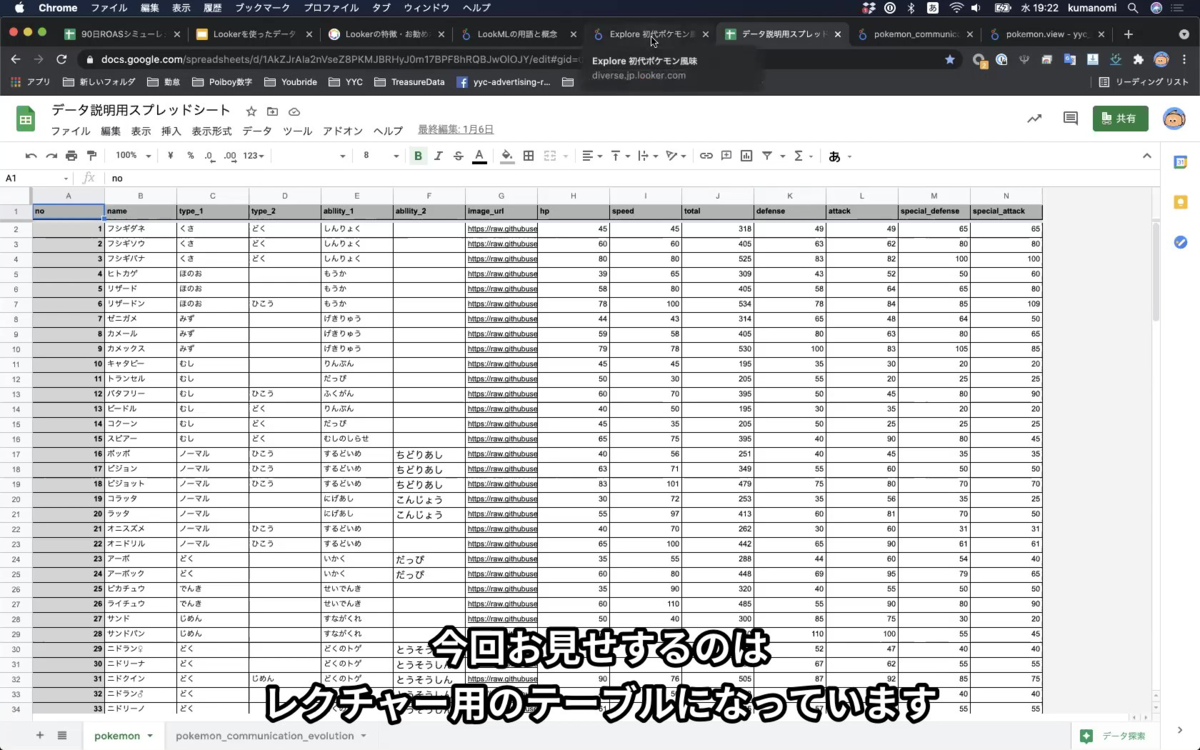
例えば、このデータから「1行目のデータ」を出してみましょう!「No.1 のキャラクター」を出してみましょう!というお題を出して、
Looker でポチポチと選んで実行するとデータが表示されます。

ここまでできれば、Filter を使って、表示したい内容を実行して結果を得るという一連の流れが既にできているようなものです。
このようなものをチュートリアルとしてレクチャーすることで、まずデータに馴染んでもらいます。
それからDiverse の中のデータに触れてもらう、といった流れです。
Diverse の Treasure Data やBigQuery にもデータを飛ばしていますが、カラム数、中身の定義、項目数も多い…などの理由で、
いきなりイチから理解いただくのは難しいです。
そのため、一番最初は本当に簡単な状態からレクチャーしています。
データの扱いに慣れてもらった後「男性のログインUUは何人でしょう?」等、簡単なところからデータを出してもらい、成功体験を積み重ねていただきます。
データドリブンという意味では、段階的に抵抗をなくして「自分で出してみようかな?」と思ってもらえることが正しいのかなと考えています。
さいごに
お読み頂き有難うございました!
前編のイベントルポはこれで終了です。後編もまもなくUPするので、ぜひご覧ください!
▼Diverseの情報発信について
Diverseはこのようなイベントの他にも各所で情報発信を行っています。興味のある方はぜひ覗いてください! www.youtube.com