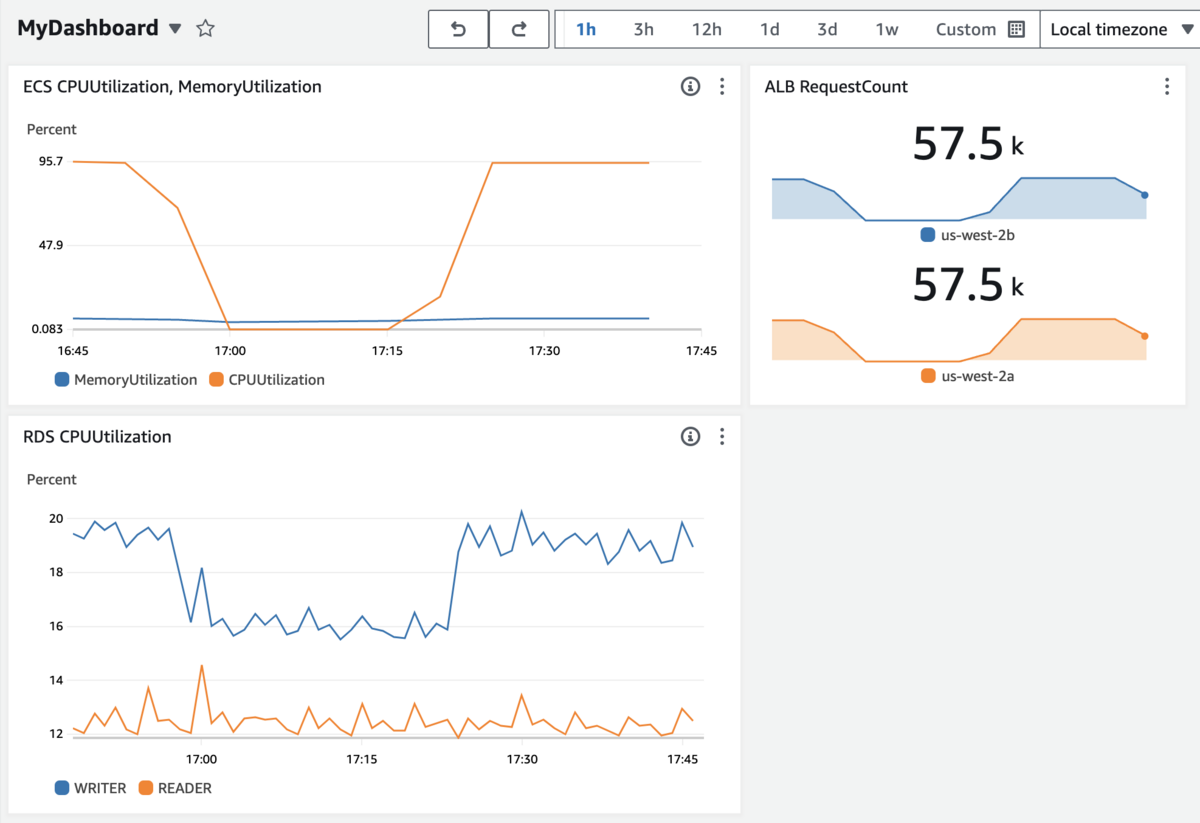
こんにちは。 Diverse developer blogです。今回は2023年のDiverseエンジニアチームの開発を数字で振り返った話をします。年間振り返りMTGにはエンジニア全員が参加して、CTOが数字をもとに年間を振り返ったあと、Miroを使ってCTO以外のエンジニアも2023年の開発を振り返りました。
{
"id": "routinesSyntaxCheck",
"title": "MySQL 8.0 syntax check for routine-like objects",
"status": "OK",
"description": "The following objects did not pass a syntax check with the latest MySQL 8.0 grammar. A common reason is that they reference names that conflict with new reserved keywords. You must update these routine definitions and `quote` any such references before upgrading.",
"documentationLink": "https://dev.mysql.com/doc/refman/en/keywords.html",
"detectedProblems": [
{
"level": "Error",
"dbObject": "mysql.flush_rewrite_rules",
"description": "at line 5,8: unexpected token 'QUERY'"
}
]
},
解決策
AWSに連絡してプロシージャをDROPしてもらうことで解決しました。
本問題は RDS for MySQL DB インスタンスから移行した DB クラスターにおいて発生する場合があることを確認しております
Message : Switchover from DB cluster dev-aurora to dev-aurora-green was canceled due to external replication on dev-aurora.
Stop replication from an external database to dev-aurora before you switch over.
と記載がありましたが、JOINするテーブルサイズから半分程度の値でストレージエンジンパラメータ(temptable_max_ram、temptable_max_mmap)を調整する対応を行いました。
この対応によりパフォーマンスがAurora MySQL version2と同等のパフォーマンスに改善しました。
まとめ
MySQL8.0に上げて良かったこと
MySQL 8系統にアップグレードしたことで、以前は使用できなかったWith句など、利用したかった機能が利用可能になり分析チームの効率が上がりました。
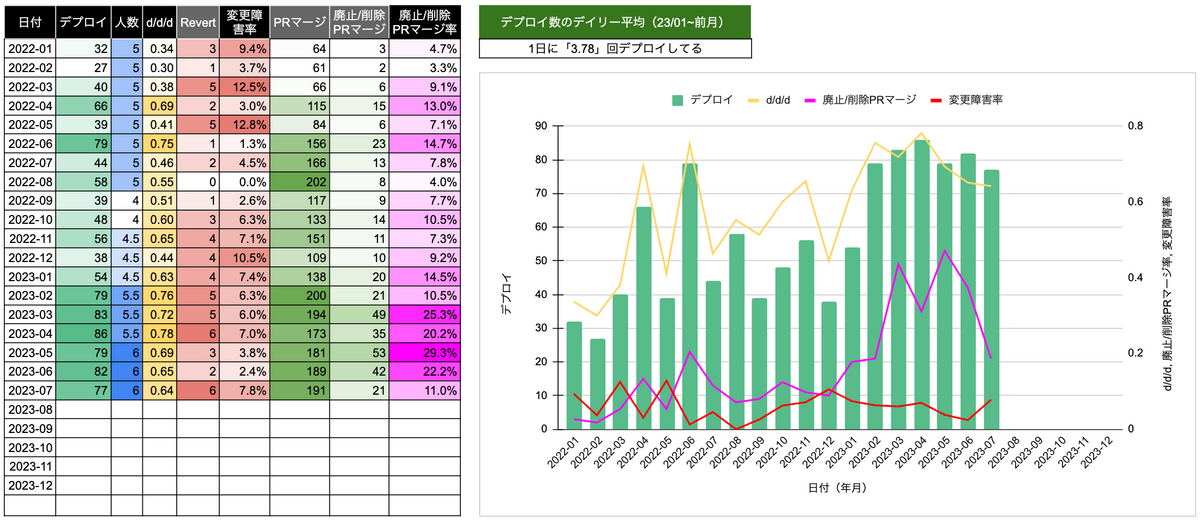
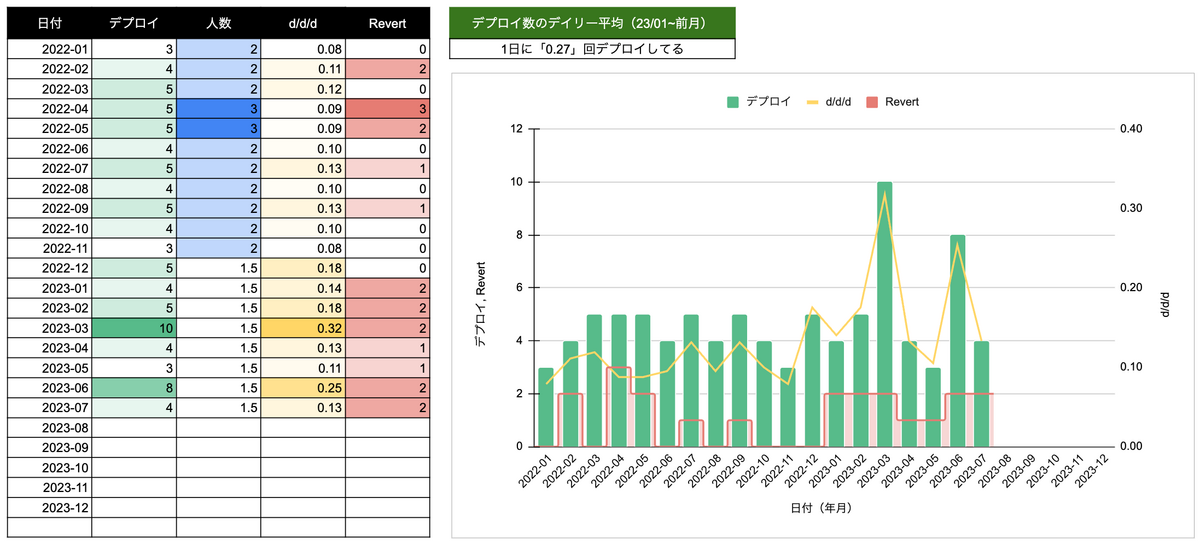
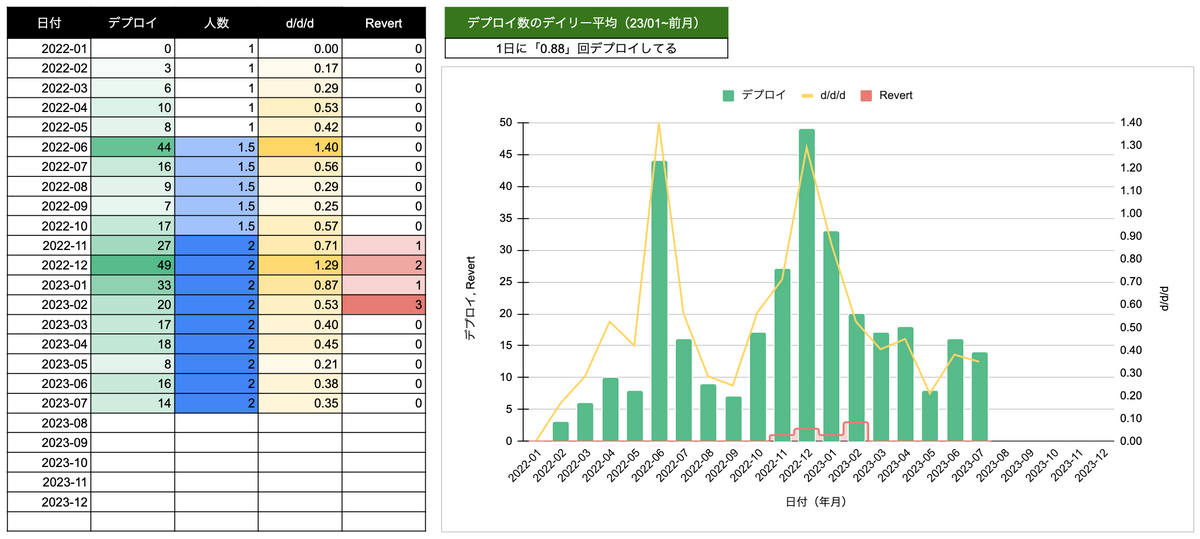
次に計測した指標は、d/d/d (deploys/ a day / a developer)です。d/d/dは、1日あたりのデプロイ回数を開発者数で割った数値で0.1以上だと、健全な開発組織と判断する指標*3です。祝日と週末を除いた営業日数を月ごとに算出しておき、現在の開発者数*4と当月のデプロイ数を計測してd/d/dを算出します。
ClientリポジトリはreleasブランチにPRをマージすると、CI/CDでAppleやGoogleのコンソールに次回のバージョンをアップロードします。弊社のiOSとAndroidはこのタイミングをデプロイとカウントします。そして、弊社のスクラムは1スプリントを5日(土日祝日を除く1週間)にしています。つまり、5日に1度はデプロイする頻度(0.27回 x 5日 = 1.35デプロイ/週)だと言えます。
変更障害率とRevert数の計測
Four keysの「変更障害率」はRevertのコミット数を代用して計測しています。コミットメッセージの先頭にRevertやrevertのメッセージが含まれるコミットが対象です。弊社では、デプロイの変更に問題があった場合、 git revert して復旧作業を行います。Revertのコミット数を計測するGitコマンドは以下のとおりです。