Diverseの須藤(id:kurotyann ) です。
今回はリプレイスの結果の後編を共有します。
主にフェーズ1〜2の技術的な知見について書きました。
なお、「前編:歴史ある婚活サービスyoubrideをリプレイスしようとしていた話 - Diverse developer blog 」でもお伝えしたとおり、このリプレイスは今年3月に経営判断により終了しました。残念ながらバックエンドのNestJSはプロダクションにデプロイされることなく終了しました。NestJSは多数の会社でプロダクション運用の実績があり、採用する価値のあるフレームワークです。弊社も本番へデプロイして、さらなる知見を得てコミュニティに還元したかったのですが、それは次回のプロジェクトへ持ち越しとなりました。
このブログでは本番デプロイは叶わなかったものの、それでもニーズがありそうな知見に絞って成果を報告したいと思います。
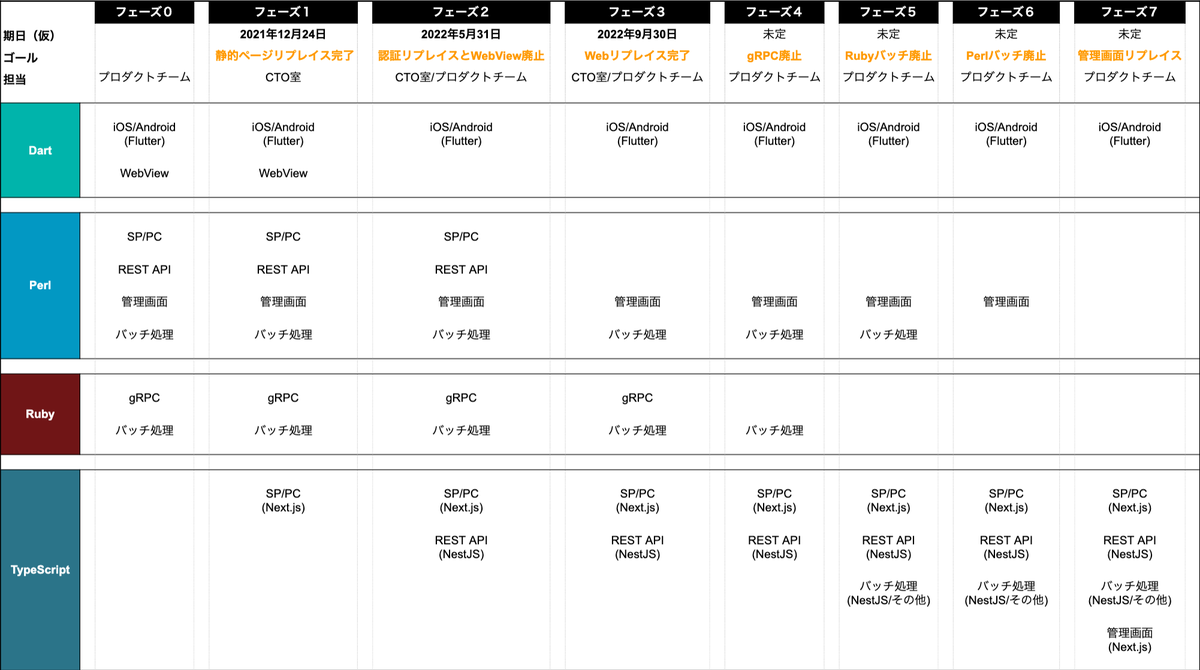
TypeScriptを主軸にした構成
このリプレイスを開始した昨年10月に弊社の開発言語をTypeScriptとDartに統一する方針を定めました。弊社のエンジニア組織の体制を考慮したとき、この二つの言語への投資が最もユーザーのニーズに応えやすい体制になると考えました。詳細は、以下の記事を参照してください。
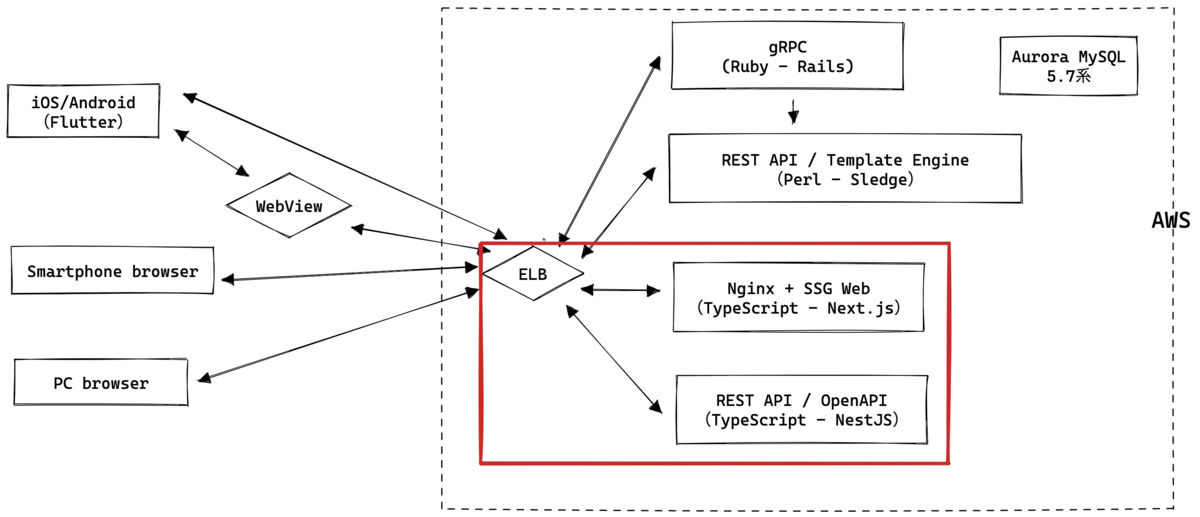
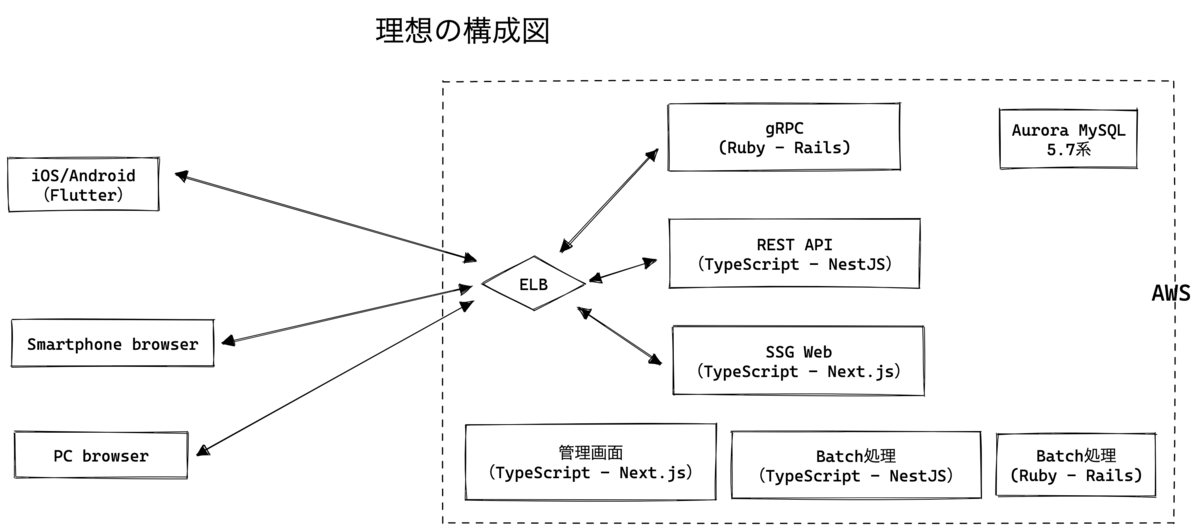
このリプレイスは、TypeScriptとDartのメリットを実感するためのプロジェクトとして開始した一面もあります。DartはモバイルアプリをFlutterで開発中のため、TypeScriptはモバイル以外を担当する言語となります。今回はフロントエンドにNext.jsを、バックエンドにNestJSを採用しました。どちらもTypeScriptをフルサポートするフレームワークで、フロントからバックエンドまで同じ言語で、かつ各種npmパッケージ(ESlintやPrettierなど)の恩恵を受けながら開発できます。
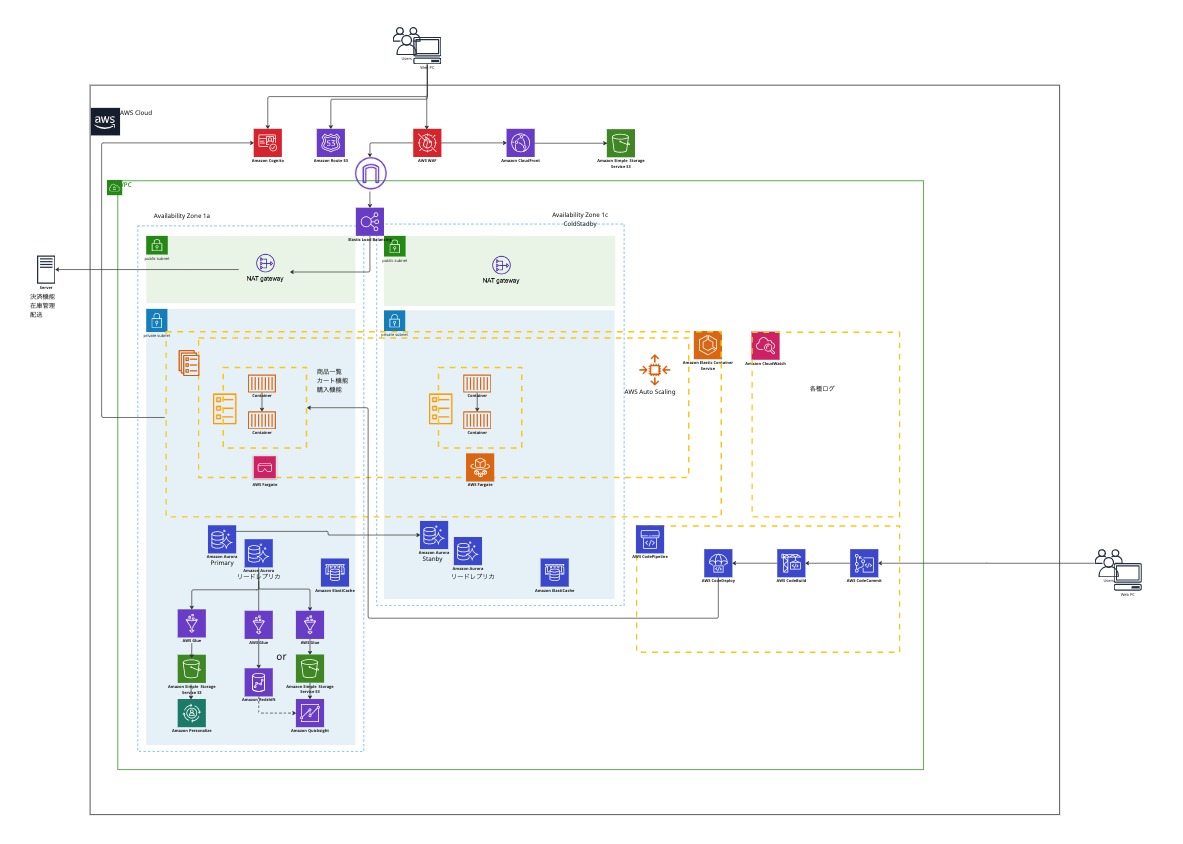
リプレイスは前編で説明したように、利用規約などの静的なページから移行を開始しました。既存の構成に、Next.jsやNestJSをAWS ECS(Fargate)で追加し、ELBのルーティングを修正するのがリプレイスの主な開発フローです。赤枠が今回のリプレイスで追加修正されたリソースです。
リプレイスで追加修正されたリソース(赤枠)
Next.jsは静的なページをSSGで生成し、生成したファイルのキャッシュをNginxが担当するシンプルな構成にとどまりました。この後編ではTypeScriptで統一した開発環境や、NestJSやPrismaなどのニーズの多そうな知見に絞って紹介したいと思います。
1. Monorepo構成
TypeScriptで統一したので、リポジトリもモノリポ構成にしました。リポジトリのディレクトリ構成を簡単にした図がこちらです。
.
├── api
│ ├── infra
│ ├── initdb.d
│ ├── prisma
│ ├── src
│ └── test
├── mobile
│ └── api-client
├── openapitools.json
├── renovate.json5
└── web
├── cypress
├── infra
├── nginx
├── public
└── src
└── api-client
apiがNestJS、webはNext.jsのディレクトリです。mobileのディレクトリは、OpenAPI Generatorで自動生成したAPIクライアントのディレクトリです。別リポジトリで開発中のFlutterの pubspec.yaml から参照しています。モバイルだけでなく、webにもOpenAPI GeneratorでAPIクライアントコードをsrcの直下に自動生成しています。
apiとwebにあるinfraディレクトリには、CI(GitHub Actions)でECS(Fargate)へデプロイするときに参照する task-definition.json や Dockerfile を環境別に配置しています。TerraformとFlutterはリプレイス前から別リポジトリで管理中なので、このモノリポに含めません。
課題
今回は、NxやlernaやTurborepoなどのモノリポ管理ツールは利用しませんでした。npm の --prefix や、各ディレクトリに配置した Makefile にコマンドを集約して、make -C ../api command_name でコマンド実行を楽にしていました。
モノリポ管理ツールは、npmの共通パッケージを集約してビルドキャッシュできるなど利点はあるものの、今回のリプレイスに必須ではないと判断して見送りました。次回で挑戦します。
2. NestJSはDDDベースのModule分割
NestJSはModuleごとに機能を隔離するアーキテクチャをとり、Moduleごとの複雑さを管理しやすくする設計をサポートしています。しかし、機能の分割単位を誤ると、Module同士の依存関係が増えてコードが密結合になり、開発が大変になります。弊社のModuleは以下のDDD構成です。
/**
* プレゼンテーション (Controller)
* ↓
* サービス (Service)
* ↓
* ドメイン (Domain)
* ↑
* インフラ (Repository)
*/
api/src/modules
└── auth
├── auth.controller.ts
├── auth.module.ts
├── domain/
├── dto/
├── repository/
└── service/
弊社ではModuleはドメイン単位で分割して、Module同士が依存する関係を避けるようにしました。つまり、Moduleから他のModuleを呼び出すのは原則禁止です。モジュール内に影響を閉じ込める設計を優先します。その代わり、Module間で似たような処理が重複するのは許容しました。例えば以下のとき、重複を許容します。
リポジトリ層で、userテーブルの呼び出しが多数のモジュールに記載される。
ドメイン層で、似たようなモデルや処理が記載される。
しかし例外として、どうしても共通Moduleとして切り出す方が効率的である場合は common/ に切り出します。なお、この共通モジュールはプレゼンテーション層(controller)を持ちません。そして、ドメイン知識を含まないもの、共通利用が確実な小さな処理は、utils/ に切り出しました。最後に、環境変数やORM(Prisma)など、あらゆる箇所から呼ばれるModuleを @Global にしてlibs/ に配置します。
api
└── src
├── libs
│ ├── config
│ ├── prisma
│ └── sentry
├── modules
│ ├── auth
│ ├── common
│ ├── health-check
│ └── user
└── utils
└── validator
└── class-validator.ts
課題
このModuleとディレクトリ構成で開発した期間がまだ数ヶ月なため、大きな課題はありませんでした。ただ、リプレイスを進めてコードが増えると、この設計でも辛みがでるかもしれません。そこは次回のプロジェクトで試行錯誤したいところです。
3. テスト時のPrismaのseedデータのリセット
開発時のテストデータや、テストケースごとのseedデータのリセット方法です。DBの初期化とユーザー作成は docker compose up 時に docker-entrypoint-initdb.d/init.sh で可能です。
// api/initdb.d/init.sh
#!/bin/bash
mysql -u root -ppassword < "/docker-entrypoint-initdb.d/0_setup/database.sql"
テーブル作成とseedデータのリセットもPrismaで簡単にできます。api/prisma/seed.ts に投入データを非同期で書きます。
// api/prisma/seed.ts
import { PrismaClient } from '@prisma/client'
import { createTestUser } from './seeds/user'
const prisma = new PrismaClient()
async function main() {
// test user
await createTestUser(prisma)
}
main().catch(e => {
console.error(e)
process.exit(1)
})
// api/prisma/seeds/user.ts
import { PrismaClient } from '@prisma/client'
export const createTestUser = async (prisma: PrismaClient): Promise<void> => {
await prisma.user.upsert({
where: {
id: 1,
},
update: {},
create: {
id: 1,
email: 'test_user01@local.youbride.jp',
gender: 1,
birth: new Date('1980-12-24'),
status: 1,
created_at: new Date(),
updated_at: new Date(),
},
})
}
あとはDBコンテナが起動中に docker compose run --rm nestjs npx prisma migrate reset --force すれば、DBがテストデータの初期状態にリセットされます。ローカルで開発中に何度でもやり直しが効くので便利です。
これを単体テストやE2Eテストをjestで走らせたとき、テストケースごとにやりたい場合 beforeAll などで、 execPromisify('npm run prisma:reset') を呼び、無理やりDBをテストデータの初期状態にリセットしていました。
import { exec } from 'child_process'
import util from 'util'
const execPromisify = util.promisify(exec)
/**
* prisma:reset は以下を実行する
* 1. DBテーブルを削除
* 2. DBテーブルを作成(migration)
* 3. DBテーブルにシードデータを投入(seed)
*
* @see api/prisma/migrations
* @see api/prisma/seeds
* @see api/prisma/seed.ts
* @see https://www.prisma.io/docs/guides/database/seed-database#integrated-seeding-with-prisma-migrate
*/
export const resetDatabaseTables = async () => {
// package.json の scripts に
// "prisma:reset": "npx prisma migrate reset --force" がある前提
await execPromisify('npm run prisma:reset')
}
// auth-signup.repository.spec.ts
import { resetDatabaseTables } from '@/../test/utils/prisma/prisma-util'
beforeAll(async () => {
await resetDatabaseTables()
const moduleFixture: TestingModule = await Test.createTestingModule({
imports: [ConfigModule, PrismaModule],
providers: [AuthSignupRepository],
}).compile()
repository = moduleFixture.get<AuthSignupRepository>(AuthSignupRepository)
})
課題
この対応でテストケースごとにDBの状態を気にすることなく、テストコードが書けます。しかし、参照するDBが一つなのでテストを直列で実行(jest --runInBand)しないと実行順やタイミングでテストが失敗します。 さらに、直列なのでテストケースの増加に比例してテスト時間も増えるし、npm run prisma:reset も毎度2~3秒かかります。
ぱっと思いつく解決策として...
テスト時に参照するDBを複数にする
DBの状態に依存しないテストケースと、そうでないケースを別ディレクトリに分ける
DB接続は諦めてテストデータをモックにする
などがありそうです。テストを書くモチベーションに直結するので、次回のプロジェクトでは良い解決策を見つけます。
ELBのルーティングルール管理
TypeScriptやDartの話だけでなく、リプレイスの苦労も共有します。一番苦労したのは新旧画面のルーティングです。
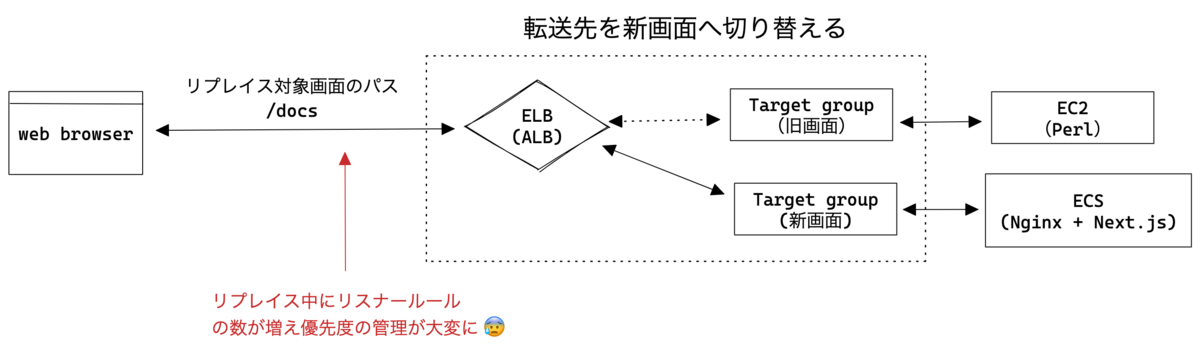
段階的に画面をリプレイスする場合、画面のパスを新旧で別にして共存させるか、パスの転送先を新旧で切り替えるかだと思います。弊社では後者を選びました。
ELBのルーティング
課題
このとき、新画面のルールを旧画面のルールより優先するようにTerraformで書く必要があります。つまり、aws_lb_listener_rule の priority を期待するルールの昇順に並び替えないといけません。しかし、terraform applyしたとき、もし既存ルールの優先度と追加したルールが重複すると、applyが中断されてルーティングが崩れた状態でaws上にリスナールールが構築されます。
追加ルールと、既存ルールの priority が重複しないか確認しながら、terraform apply するよりも、awsコンソールから手動でルールを追加後、優先度が変わったルールを terraform import する方が安全だと判断し、フローを変更しました。
① 新ルールを既存のルールの優先度と被らないように追加する
resource "aws_lb_listener_rule" "example-replace" {
listener_arn = aws_alb_listener.production.arn
priority = local.replace-base-priority + 2 // 次のルールは重複を避けて3にする
② 追加したルール数に合わせて、XXXX-rule-countを変更する
locals {
base-priority = 1
base-rule-count = 1
replace-rule-count = 3
replace-base-priority = local.base-priority + local.base-rule-count
prod-base-priority = local.replace-base-priority + local.replace-rule-count
}
③ PRレビューはするがmasterには一旦マージしない
①と②の修正をレビューしてもらう
マージすると優先度の重複で失敗する可能性があるのでマージはしない
④ AWSコンソールで対応する環境のリスナールールに ① のルールを追加する
⑤ ルールが正常に切り替わったらterraform import でルールを追加する
⑥ terraform plan で差分なければPRをmasterにマージする
awsコンソールで新ルールを手動追加しつつ、terraformのローカル変数でルールの重複を避ける作戦です。あまり賢い解決策ではないので、ここも良い解決方法を模索したいです。
最後に:成果をつなげていく
これまでDiverseはPerl、Ruby、Dartでの開発経験はあるものの、TypeScriptでの開発経験や歴史がまだ浅い会社です。リプレイス中は、毎週火曜日に弊社で技術知見共有会(Tech-DLN)を開き、TypeScriptをはじめリプレイスで得た知見を社内に共有していました。リプレイスを機会に社内での技術共有が進みはじめたので、その推進力を次のプロジェクトへと繋げます。
リプレイスは終了しましたが、次のプロジェクトでもTypeScriptとDartでの開発を続ける予定です。このような開発体制に興味のある方、もっと良いやり方があるなど、カジュアルに話したいことがある方は是非お話しましょう!